
Les bases de données graphes pour modéliser la connaissance
Le KM (Knowledge Management) sera sans doute demain l’un des domaines moteurs du système d’information. Tant il deviendra vital, pour des questions de concurrence et d’efficacité, de faire l’inventaire et de classer le corpus de connaissances de l’entreprise. Les données et la connaissance sont le « sang de l’entreprise », alors que le TI lui-même n’est que l’outil qui tente d’en faire le meilleur usage. L’une des principales difficultés du cheminement KM est de modéliser ces connaissances et d’établir les liens entre elles, pour pouvoir les retrouver ensuite. L’une des techniques en fort développement consiste à les représenter graphiquement, en exploitant les ressources d’un SGBD orienté graphe, sur fond de modélisation conceptuelle. Nous invitons nos partenaires à se pencher sur ce concept, appelé à « booster » un domaine…qui, pour l’instant, n’avance pas.
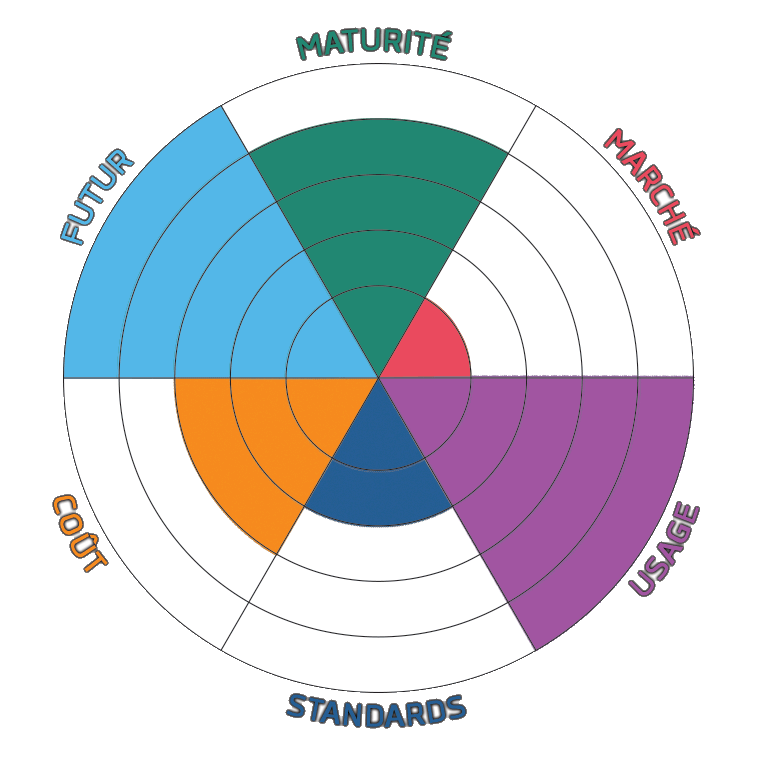
Les critères sont évalués de 1 à 5
- Marché
- Présence réelle sur le marché.
- Usage
- Intérêt potentiel, hors considérations commerciales
- Standards
- Niveau de standardisation du sujet
- Coût
- Intérêt potentiel, hors considérations commerciales
- Futur
- Niveau de crédibilité prévisible
- Maturité
- Niveau de maturité atteint actuellement
Comprendre le modèle en couches des "generative AI "
Les données personnelles : une bataille perdue d'avance
Intelligence Artificielle : l'énigme de la conscience
DAS cellulaire : les architectures distribuées d'antennes
Module ARCHITECTURES du système d’information et technologies du datacenter