En direct avec LeMarson
Vos rendez-vousen directavec LeMarson
pour ne rien rater de l'actualité et des grandes thématiques des tendances informatiques.

Grace Hopper et Bjarne Stroustrup, une même flamme à 30 ans d’intervalle

La machine de Turing, une référence théorique

L’état de l’art de la vision par ordinateur

Les religions et l’Intelligence Artificielle

Le labyrinthe des modes de programmation

Les bases et arbres de connaissances

Les datacenters dans le désert ou la banquise
Depuis toujours, d’immenses territoires sont réputés incompatibles avec les pratiques de notre société. Cela va changer et les datacenters seront les premiers à s’installer dans les déserts et zones froides de la planète. C’est déjà le cas.

Ouvrons les portes de la recherche TI
L’Intelligence Artificielle n’est pas une fin en soi, même si elle occupe une grande partie de nos préoccupations. La recherche dans le TI a depuis longtemps anticipé sur le futur et dégagé des voies qui continueront de nous surprendre.

Le tsunami des architectures applicatives
Il y a encore quelques années, il n’existait qu’une seule architecture applicative : monolithique. Tout était concentré en un seul lieu logique : code et données Dans les années 90, la puissance des machines aidant, certains ont imaginé le mode client-serveur en confiant une partie du traitement au local. Ce fut un désastre.

La robotique, où en est-on ?
La robotique ne peut pas être dissociée des algorithmes, car ce sont eux qui les animent de l’ "intérieur". Mais on continue de la distinguer, sans doute parce qu’elle est entrée dans les mœurs beaucoup plus tôt que l’IA.

Pleins feux sur ces inventeurs qui ont façonné le TI moderne.
Les grandes innovations technologiques qui ont marqué les 50 dernières années du TI sont rarement le résultat d’une stratégie pensée par les grands acteurs, hormis IBM qui a toujours fait confiance pour cela à ses laboratoires (sauf pour le PC), voire Xerox. En général, elles sont le résultat de fulgurances émises par des individus, tout seuls dans leur coin, qui se sont dit "pourquoi pas"…

Programmer les "mains dans les poches"
Le "vibe coding" est une autre forme d’assistance au codage. Cette fois, on n’a pratiquement plus rien à faire. Pas sûr que cela fasse plaisir à tout le monde.

L'incroyable explosion des structures de données
Bien que cela ne semble pas émouvoir les foules, l'évolution des architectures de données constituent l'une des avancées les plus pertinentes du TI de ces 30 dernières années.

Les 10 fléaux de l’Intelligence Artificielle
La plupart des usagers sont éblouis par les progrès de l’IA et continuent de s’enthousiasmer devant les prouesses des algorithmes. Nous pensons que ce n’est qu’un aspect de la technologie. Elle a aussi un côté sombre et très inquiétant, sur lequel nous nous focalisons aujourd’hui.

Ce que sont vraiment les agents intelligents
Les agents dits intelligents font une entrée remarquée dans le monde de la génération IA. Mais on dit aussi beaucoup de bêtises à leur sujet...

COMPRENDRE "enfin" les qubits
Les machines quantiques font la une des journaux et sont à l'origine de l'essentiel des migraines des responsables de TI. Nous allons y remédier.
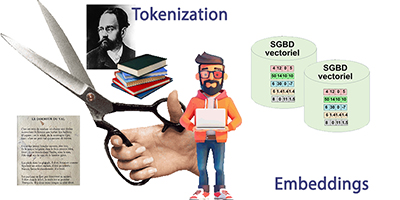
Tokens et "embeddings", c’est quoi ces trucs ?
Les développeurs qui ont à construire une application de génération IA, ne peuvent pas ignorer le découpage en tokens et leur transformation en vecteurs numériques.

La programmation du comportement des réseaux
Les réseaux sont de plus en plus accessibles à travers une interface logicielle et le concept SD-WAN est désormais incorporé dans les architectures. La capacité d'en programmer le comportement est donc une suite, on ne peut plus logique.

Le "prompt", une spécialité à part entière
Le "prompt" est passé du statut de simple invite ">" à celui de véritable technologie, voire même de science. Certains spécialistes envisageant d’en faire leur métier. Il est donc temps de faire plus ample connaissance avec lui, ses techniques et modèles à connaître.

Les véhicules autonomes, un usage contestable
Cela fait 15 ans qu’on nous annonce le déploiement de véhicules extraordinaires, à conduite autonome. Cela fait 15 ans que nous faisons remarquer que l’essentiel des problèmes n’est pas réglé.

Une première approche des réseaux neuronaux
Les réseaux neuronaux constituent un modèle de plus en plus utilisé en IA pour traiter des problèmes de reconnaissance d’objet, d’images, de mots, de sentiments, etc. Mais le plus curieux, c’est qu’en général on n’a pas une idée claire de ce dont il s’agit, car on veut absolument les confondre avec des réseaux traditionnels. Qui n’ont rien à voir.

L’intégration IoT : réapprendre le métier
Les capteurs envahissent notre quotidien et espace professionnel. Il faut maintenant les intégrer dans le TI, ce qui ne se fait pas sans mal, tant nous avons pris des habitudes qui nous ont fait oublier les contraintes du développement.

L’apprentissage des algorithmes d’IA
Tous les algorithmes d’IA passent par une phase d’apprentissage, qui permet à leurs usagers de les adapter aux tâches qui leur seront confiées. Au départ, ils ne savent rien faire, mais à force de patience et d’entraînement, ils finissent pas être pertinents.

L’architecture Intel x86, seule contre tous
On le pressentait depuis longtemps. A savoir que le jeu d’instructions x86 d’Intel ne pourrait pas conserver éternellement son quasi-monopole sur l’ensemble du spectre des machines : serveurs, postes de travail, smartphones, etc. Cette fois, on y est et les patrons de TI sont invités à faire des choix et élaborer une stratégie dans laquelle Intel pourrait manquer à l’appel.

Ray Kurzweil et Yann Le Cun, deux personnages que tout oppose
Dans notre série "deux noms, deux destins", jamais sans doute nous n’avons opposé deux individus aussi dissemblables : Ray Kurzweil, adoré aux Etats-Unis et futurologue "honoris causa" de 20 universités et Yann Le Cun, chercheur franco-américain, à l’origine de nombreuses avancées, dont celle des réseaux neuronaux profonds.

Le futur de la cryptographie : aie !!!
A peine maîtrisons nous les algorithmes de cryptographie classique, symétriques, asymétriques et mixtes, qu’il faut nous intéresser à autre chose, à l’usage des machines quantiques et aux nouveaux algorithmes, elliptiques, etc. On a malheureusement une longueur de retard sur les criminels.
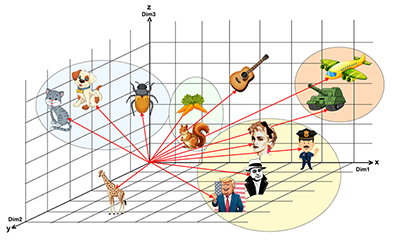
Les bases de données vectorielles
Indispensables à l’Intelligence Artificielle, les SGBD vectoriels et les représentations logiques qui leur sont associées, sont désormais incontournables pour exploiter les vecteurs de dimensions élevées, tels que ceux que l’on trouve dans les LLM et plus généralement dans les outils de génération IA.

L’intrusion de l’IA dans la programmation
La situation est paradoxale. D’un côté on nous dit que les utilisateurs ne vont plus programmer, la fonction étant reprise par des professionnels, généralement implantés dans le Cloud et de l’autre on nous bombarde d’innovations, la dernière en date étant l’apport de l’Intelligence Artificielle sur le codage. Il faudrait savoir…

La perception religieuse de l’IA
Par rapport aux doxas communément admises, l’Intelligence Artificielle est un éléphant dans un magasin de porcelaine. Elle a tendance à remettre en cause certains fondamentaux, plus précisément ceux issus de nos croyances philosophiques et religieuses, que l’on croyait pourtant à l’abri des séismes.

L’IA et la perte d’emplois
Il faut être aveugle ou inconscient pour ne pas comprendre que l’Intelligence Artificielle va changer profondément le monde de l’emploi.

Les agents intelligents : faut-il s’en inquiéter ?
Les agents intelligents constituent la grande nouveauté d’une Intelligence Artificielle, qui pourtant n’en est pas avare. Sauf que cette fois, on entre dans le "dur", dans les vraies problématiques, jusqu’ici à peine entrevues : ces agents sont-ils là pour nous aider ou au contraire, nous remplacer.

Structures de données : la perspective des langages
Il y a 2 manières d’aborder le problème des données en termes de développement. : par l’architecture intrinsèque et leur perception depuis les langages. C’est ce second point de vue que nous vous proposons de traiter dans ce webinaire.

La 6G est à nos portes. De quoi s’agit-il ?
On se dirige vers un monde du transport télécoms à 2 acteurs : les mobiles et la fibre optique. Les autres ne seront que des compléments de circonstances. D’où l’importance de la nouvelle norme 6G qui ne tardera pas à envahir notre environnement.

POO, nous nous sommes peut-être trompés
La Programmation Orientée Objet a été positionnée comme une évolution positive du codage impératif (C, Cobol…). Un monde nouveau qui ne pouvait qu’être avantageux. A vrai dire, nous n’en sommes plus très sûrs.

Informatique spatiale, le TI n’est pas un jeu vidéo
Les fabricants, Apple et les autres, ont décidé qu’il fallait nous équiper d’un casque et nous plonger dans un espace virtuel, totalement déconnecté, pour nous rendre plus efficaces. Ils ont tort.

Zero Trust : un cheminement sécuritaire, pas un objectif
Malgré les rodomontades des fournisseurs, la sécurité reste le problème n°1 du TI. Nous n’avons pas réussi à nous protéger de manière satisfaisante, pour la simple raison que les protocoles mis en œuvre depuis les années 80, sont des passoires.

Véhicules autonomes, ça ne sert à rien
On nous a vendu l’autonomie des véhicules en nous faisant croire qu’elle répondait à un vrai besoin. Il n’en était rien

Blockchain, alors ça vient ?
Sous prétexte que les réseaux sont devenus très performants, on a cru trop vite à l’avènement des architectures Blockchain. Retour sur terre.

Bob Metcalfe et Pierre Bézier, deux destins contraires
L’un, Bob Metcalfe, inventeur d’Ethernet est très connu. L’autre, Pierre Bézier, créateur des polynômes éponymes, n’évoque pas grand-chose.
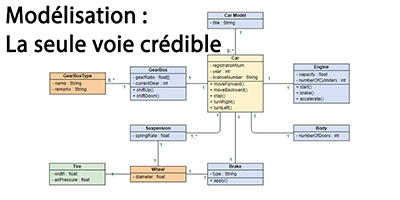
Développement : il faut modéliser
Face au codage direct, la modélisation ne prend pas. Il faudrait l’imposer.

Les leçons de 2024, les promesses de 2025...
A quoi faut-il s'attendre en 2025 ? L'exercice est classique mais néanmoins périlleux. D'autant que le TI est en pleine restructuration.

Les GAFAM et les grands procès : un leurre
Comment peut-on croire que les GAFAM seront inquiétés pour ne pas avoir respecté la loi anti-trust ?

La physique des capteurs
La 4 ème génération du TI nous nous oblige à faire connaissance avec ces petits bouts d’électronique, les IoT (capteurs). C’est ce que nous vous proposons de faire dans ce webinaire.

L’organisation du TI doit être revue
Pour bien aborder la mutation qui nous attend, il faut nous attaquer à la restructuration du TI qui n’est plus adapté.

Philosophie, technologie et religion face à l’IA
Il est des sujets que l’on n’ose pas aborder. C’est le cas de l’IA et de ses conséquences sur notre intimité et croyances. Mais il n’y a aucune raison de les éluder.

La vérité, l’impossible quête
Bien que le net ait été pensé pour garantir l’universalité et la sincérité de nos communications, il est le creuset de toutes les déviances. Qui nous font douter de tout.

La référence humaine de l’IA : une erreur d’aiguillage
Il est un idée très répandue qui veut que les capacités humaines soient dépassées à terme par les algorithmes. Sinon aujourd’hui, tout au moins demain.

Un algorithme programmeur… c’est sérieux ?
On brûle les étapes. Le programmeur IA n’a pas le "génie" des développeurs humains. Pas encore.

IT as a Service : inéluctable à terme
Après des années d’observation, le Cloud ne fait plus peur et s’apprête à accueillir le datacenter dans sa globalité.

LLM et transformers, c'est quoi au juste
Ceux qui s'intéressent à l'Intelligence Artificielle sont empêtrés dans le mouvement de fond qui agite le microcosme, avec en tête de gondole, les LLM ou "Grands Modèles de Langages", des systèmes entraînés sur des volumes de données considérables.

Le monde nouveau de l'argent
Notre rapport à l'argent a profondément changé. Nous sommes passés en quelques années d'un modèle fondé sur les agences et le contact physique au tout numérique, aux monnaies cryptographiques et au virtuel. Mais cela ne va-t-il pas trop vite ?

Les nouveaux langages de programmation
Il y aurait, semble-t-il,18 000 langages de programmation disponibles aujourd'hui. Tant il est vrai que la conception d'un langage (son compilateur ou interpréteur), autrefois réservée à une "élite qui savait" est désormais accessible au plus grand nombre.

Les mathématiques et l'IA, souvent une nécessité
Hormis quelques cas particuliers et contrairement à la doxa répandue, les mathématiques n'ont jamais servi à rien pour nous permettre de pratiquer notre métier du TI. Certes, elles pouvaient nous aider à acquérir une certaine logique de raisonnement, mais pour l'essentiel elles étaient inutiles.

Nomophobie : un pied chez les fous
En quelques années, le smartphone est devenu un compagnon dont nous ne pouvons plus nous passer. Au point d'être frappés de nomophobie, une pathologie qui s'est répandue comme une traînée de poudre.

Nanophobie et autres pathologies numériques
Des solitudes associées par le numérique n'ont jamais fait des groupes homogènes de personnes "bien dans leur peau".

Rentrée du TI : les gros joueurs inquiétés
Malgré leur puissance et le monopole de fait imposé au marché, les grands acteurs tels que Google et Microsoft sont désormais contestés. Les mois à venir seront décisifs (IA ?) pour certaines situations bien établies.

L'impossible gestion des données personnelles
La protection des données personnelles est devenue l'objectif n°1 de la plupart des gouvernements, qui voient là un moyen de se valoriser auprès de leurs citoyens. C'est effectivement une bonne idée, mais inapplicable concrètement et impossible à mener sur le long terme.

Faisons connaissance avec les consensus
Si vous vous intéressez aux monnaies cryptographiques, il y a peu de chances que vous n'ayez jamais croisé ces "drôles" de choses que sont les algorithmes de consensus. Si c'est quand même le cas, ça tombe bien, nous leur consacrons ce webinaire.

Deep et dark Web, quand le rare côtoie le pire
Il se dit qu'’il n'y a que 10 % des informations, sites, documents et médias, qui sont accessibles par un moteur classique, Google ou autre. Le reste, 90 %, se trouvent dans les couches profondes du "deep" et du "dark" web. Auxquels on accède par des moyens détournés…

Capteurs : la 4 ème génération du TI
Le système d'information prend une nouvelle dimension avec l'arrivée des capteurs. Il s'agit sans aucun doute de la 4 ème génération du TI. Nous lui consacrons ce webinaire avec l'objectif de synthétiser ce qu'induit ce passage, en termes de connaissances.

Modes de déploiements et intégration continue CI/CD
Le webinaire que nous consacrons à la diffusion des applications a pour premier objectif de remettre un peu d'ordre dans les définitions, entre intégration, livraison et déploiement, des concepts chers au monde agile et à Devops.

Les transports du futur : verts et sans pilotes
Les moyens de transport de demain doivent tout à l'informatique, aux réseaux et à l'Intelligence Artificielle. Ils ne sont cependant que la continuité de ce qui existe déjà, les pilotes en moins.

Vérité et fake news : comment être sûr…
Avec l'explosion des technologies génératives et le déferlement des fakes en tous genres, il est devenu quasiment impossible de se prémunir contre le trafic de la vérité, sur laquelle l'essentiel de nos activités professionnelles et personnelles sont pourtant fondées. Les années qui viennent marqueront les débuts d'une ère nouvelle, celle de l'incertitude.

Les grandes utopies du TI : capitaliser sur nos erreurs
Depuis 1964, de nombreuses innovations se sont révélées inadaptées et ont été abandonnées. Au-delà des discours de façades, allons-nous, enfin, apprendre de nos erreurs.

Backup et restauration des datacenters
Le backup et la restauration des gros volumes de données, reste une fonction régalienne hyper-sensible des datacenters

L'hyperconvergence pour le reliquat des TI internes
Toutes les ressources n'allant pas dans le Cloud, les futures installations locales, serveurs et réseaux, seront conçues pour ne pas induire de contraintes lourdes aux usagers. C'est dans ce contexte que les systèmes hyperconvergés seront incontournables qui libèrent les TI de l'essentiel de ce qui fait leur quotidien d'aujourd’hui.

"Smart contracts" : la dématérialisation non contrainte démarre
Le concept de contrats intelligents ou "smart contracts", imaginé par Vitalik Buterin dans le cadre d'Ethereum, est susceptible de lancer définitivement la dématérialisation non contrainte, non imposée par une organisation gouvernementale.

Ce qu'il faut retenir de 2023
L'année qui se termine a été l'une des plus "éprouvantes" parmi celles que nous avons eu à affronter depuis l'avènement du PC en 1981. Les fondations du TI ont tremblé et certaines de nos certitudes ont volé en éclats. Espérons que 2024 sera plus calme…

L'hyperautomatisation : les temps modernes du TI
L'hyperautomatisation est parfois considérée comme une avancée majeure du TI. Associée à la transformation numérique, elle n'est pourtant que son évolution logique.

Productivité, il n'y a pas qu'Office. Ah, bon ?
Office représente plus de 95 % des utilisateurs de bureautique. La concurrence, bien que discrète, n'en est pas moins réelle, surtout orientée SaaS dans le Cloud.

Les grandes figures du TI... dont on parle moins
Il n'y a pas qu'Elon Musk et Bill Gates dans la planète TI. D'autres personnages, moins médiatisés ont aussi joué un rôle essentiel et certains sont de parfaits inconnus.

La fédération d'identités : "you will never walk alone"...
Les SI des entreprises communiquent entre eux et se doivent de partager certaines ressources, dont les données d'authentification. D'où la nécessité de passer par une fédération.

Sécurité : les reproches faits à la suite TCP/IP
Les protocoles de la pile TCP/IP, conçus, à la fin des années 70, sont une calamité sécuritaire. Mais que leur reproche-t-on au juste ?

Quand la biométrie sort des sentiers battus...
De technologie d'avant-garde et utile, la biométrie prend parfois des allures de folklore délirant... Ce qui nuit à sa crédibilité.

Pourquoi l'IA est-elle stupide ? Elle nous imite...
L'IA est tout sauf intelligente. C'est un abus d'expression et il faut parler de simulation.

Ethereum, au coeur de l'Internet de demain
Internet se rationalise et Ethereum apparaît comme la force montante de l'écosystème. C'est le transactionnel de demain, au coeur du Web3.

Oracle, Intel et IBM, colosses aux pieds d'argile
Qui aurait pu prévoir que nous oserions au moins nous poser la question ? IBM, Intel et Oracle ont-ils de l'avenir.

La vérité sur les liens santé - ondes électromagnétqiues
Il est de bon ton de se plaindre dès qu'un opérateur implante une antenne à proximité. Mais qu'en est-il vraiment ?

L'enseignement de demain : pour éviter le désastre
Au fur et à mesure que les technologies progressent, les capacités cognitives des apprenants diminuent. On approche du "zéro absolu".

Les hackers qui ont marqué l'histoire
Depuis le premier ver Brain écrit par 2 pakistanais, la cybersécurité s'est développée à travers la planète, avec des millions de malwares et surtout une population qui en veut de manière viscérale aux institutions en place.

La distribution de demain : la révolution du quotidien
Sous la poussée d'Amazon, le "retail" en général bascule dans un processus virtualisé où l'usager est libéré de toute contrainte, hormis celle de disposer sur son mobile d'un compte reconnu. John Patterson, fondateur de NCR doit se retourner dans sa tombe.

MV et conteneurs : pourquoi les opposer
Pendant 20 ans, on a opposé les machines virtuelles aux conteneurs. Désormais, la tendance est plutôt au rapprochement.

L'ultime bataille : Intel contre ARM
Le règne ininterrompu d'Intel sur le marché des processeurs complexes (x86/CISC) est désormais contesté. ARM et sa technologie RISC est présent sur les serveurs, les IoT et les mobiles. L'affrontement ne fait que commencer.

La vie privée, c'est fini... il faut s'y faire
Cela fait des années que l'on s'inquiète de la disparition probable de notre vie privée. Les états légifèrent, les usagers s'insurgent et pendant ce temps, les GAFAM font commerce de nos données. Cherchez l'erreur !

Programmation quantique et drones, c'est aussi du codage
Les machines quantiques et les drones apportent un souffle nouveau au métier de programmeur... qui en avait bien besoin.

Le "tout en un" de l'hyperconvergence
L'hyperconvergence, qui est une forme nouvelle d'intégration, a de plus en plus de succès. C’est une solution séduisante, qui pose cependant le problème de l'interlocuteur unique et du manque de qualités de certains composants.
ChatGPT, doucement, on se calme...
Depuis la fin 2022, ChatGPT est accessible au grand public. Nous entrons dans une ère nouvelle, celle d'une probable révolution (très) inquiétante.

Bilan 2022 : tout va vite, trop vite
2022 a été marqué par de nombreuses initiatives technologiques, avec 3 axes majeurs : le virtuel, l'IA et le cloud.

Kubernetes, le Windows des conteneurs
Certes, ce n'est pas la même chose et Kubernetes, que l'on appelle aussi K8s, n'intervient pas au même niveau que Windows et ce n'est pas un OS. Mais fort du "soutien" de Google, il est et sera incontournable pour l'administration des conteneurs.

Les nouvelles protections périmétriques du TI
En matière de protection périmétrique, on a trop tendance à faire confiance aux infrastructures courantes, qui certes se sont renouvelées, mais qui ne manquent pas de faiblesses.

Vers l'authentification invisible et permanente
Les mots de passe ont fait leur temps et ils ne servent quasiment plus à rien. De nouvelles technologies apparaissent pour les remplacer, qu'il faut connaître, moins contraignantes et surtout moins hasardeuses.

Les algorithmes de chiffrement, ces inconnus
Le chiffrement -ne pas dire cryptage et encore moins chiffrage- est présent partout. Mais on n'a pas nécessairement une idée précise de ce qu'il recouvre et des grands familles dont il est constitué.

Le TI et la gestion des énergies
L'énergie que l'on avait tendance à oublier fait une entrée remarquée dans les préoccupations des responsables de TI. Contraints par une règlementation récente et des "lobbies" actifs, les TI ne peuvent plus faire bande à part. La difficulté vient toutefois de ce qu'il s'agit de problèmes nouveaux, souvent mal compris.

Les bases de données distribuées
Tout est distribué aujourd'hui. Les infrastructures matérielles, les réseaux et les applications. Les bases de données suivent le même mouvement avec leur 5ème génération.

WebAssembly et LLVM, pour de meilleures performances Web
Compte tenu de ce que la grande majorité des applications auront une interface Web et seront accessibles via un navigateur, se pose le problème de leurs performances. WebAssembly du W3C et LLVM, sont deux technologies à prendre en compte.

L'autisme au service du TI
Les grands acteurs de l'informatique, SAP, IBM, etc, ont compris depuis longtemps tout l'intérêt que présentent certains autistes "hyperactifs", comme les désigne Fabienne Cazalis, dans un environnement informatique exigeant. Le problème est que pour la majorité d'entre nous, l'autisme reste une maladie, considérée comme une "anormalité".

Le cellulaire privé contre Wi-Fi
Traditionnellement, Wi-Fi est réservé aux installations internes, alors que le cellulaire revendique une portée plus universelle. Ce distinguo est en train de disparaître avec l'émergence des réseaux cellulaires privés.

Non, Cobol n'est pas un "gros mot"…
Il reste aujourd'hui plus de 300 millions de lignes de programmation Cobol. Ce qui constitue un problème dans la mesure où les développeurs "modernes" ne veulent pas pratiquer un langage qui a près de 70 ans…

Pleins feux sur les "smart contracts"
Il faut se faire une raison, la dématérialisation est un échec. La raison : il est très difficile de prouver sa bonne foi, en cas de conflit. Les "smart contracts" répondent à cette préoccupation.

C2C : secours inter Clouds
La mode est à l'hybride. Pour faire fonctionner une application "à cheval" sur deux espaces : Cloud et local ("on premise"), voire entre deux Clouds. Ce qui induit la nécessité de passer d'un Cloud à l'autre, sans risques. Le problème est là, compter sur une fédération homogène de solutions Cloud et ne pas risquer l'enlisement dans un Cloud propriétaire…

Ce qu'il faut savoir des langages
Contrairement aux idées reçues, la pratique des langages est d'autant plus nécessaire qu'une large partie des projets applicatifs est partie à l'extérieur. D'où la nécessité de maintenir un haut niveau de compétences.

Les micro-cartes Raspberry, Arduino…dans l'entreprise
Les micro-cartes Raspberry Pi, Arduino et les autres, sont bien autre chose qu'un simple hobby pour "geeks" en mal de technologie. Leur apport est désormais essentiel et ils contribuent autant à la formation interne qu'à de véritables projets industriels.

Le "tout en un" de l'hyperconvergence
L'hyperconvergence, qui est une forme nouvelle d'intégration, a de plus en plus de succès. C’est une solution séduisante, qui pose cependant le problème de l'interlocuteur unique et du manque de qualités de certains de ses composants. .

C'est la rentrée
La restructuration du TI commence dès cet automne...

L'assistance "intelligente" au codage
L'IA permet désormais de générer du code source à partir d'un modèle d'application. Le résultat obtenu est stupéfiant, qui intègre même nos "manies", habitudes et défauts. De quoi être déstabilisé.

DaaS : le cloud pour les besoins complexes de données
Les applications sont de plus en plus exigeantes en termes de données, architecture, performances et sécurité, ce qui se traduit par de grosses difficultés de mise en oeuvre, que les entreprises ne sont pas nécessairement prêtes à prendre en compte. C'est là qu'interviennent les outils de DaaS ("Data as a Service"). Une petite révolution initiée par le Cloud.

La calamité de l'obsolescence programmée
Croire que l'on achète des équipements ou des logiciels est une erreur. Nous achetons des durées d'usage de ces équipements, aux termes desquelles nous devons les changer. C'est une malversation difficile à éradiquer..

Les incroyables progrès des neurosciences
Ne touchez pas à mon cerveau : je ne sais même pas comment il fonctionne !!! Dans le sillage des compagnies GAFAM spécialisées dans les communications avec le cerveau, il faut s'attendre à des bouleversements extraordinaires.

Le "bore out", il faut l'affronter
La robotisation et l’automatisation contribuent à faire disparaître de nombreux métiers et ont donné naissance à une catégorie nouvelle d’employés…qui n’ont quasiment rien à faire. On les trouve surtout dans les grandes entreprises.

Big Data, une escroquerie mondiale
La déception qui entoure les réalisations "Big Data" sont à la hauteur des espoirs que les promoteurs avaient fait naître. Contrairement à ce qui nous a été dit, il y avait loin de la coupe aux lèvres.

L'état de l’art des villes intelligentes
L'état d’esprit qui règne dans les fameuses "smart cities" ou villes intelligentes est plutôt orienté déception. La faute aux difficultés quasi-insurmontables rencontrées pour fédérer les services.

La gestion des identités et des habilitations dans le Cloud
Il va falloir choisir. Soit on confie au Cloud le soin de gérer les habilitations et les droits d’accès du TI, soit on conserve notre indépendance, avec les risques d’interruption de service. A chacun son métier.

Avec l'IA, la démocratie n'est-elle pas devenue un leurre ?
L'Intelligence Artificielle risque de se déployer dans des domaines auxquels on n'avait pas pensé au début, les élections et la simulation "politique" des comportements citoyens.

Les microservices, séduisants et difficiles
L'urbanisation a fait de gros progrès dans les officines de développement. Si les SOA chers au Gartner a montré ses limites, les microservices sont désormais incontournables. Qui ne sont pourtant pas dénués de problèmes.

Les métavers et la folie du virtuel
Le covid a profondément perturbé nos méthodes de travail. Le télétravail s'est généralisé, mais surtout les comportements virtuels se sont généralisés, dont les métavers sont l’exemple le plus déconcertant… et peut-être le plus inquiétant.

Les machines scientifiques et l'exaflopique
En 1985, les machines scientifiques les plus performantes culminaient à 1 GFlops. Depuis, leurs capacités ont été multipliées par 1 000 tous les 11 ans et ont dépassé les PetaFlops en 2008.

Autisme et informatique
L'autisme est à la fois inquiétant et fascinant. Dramatique pour les familles et les autistes eux-mêmes, mais également extraordinaire quant aux fantastiques capacités de ces "gens venus d'ailleurs".

Des capteurs dans le corps
Après des années d'hésitations et d’interrogations éthiques, il semble bien que les barrières sautent, celles qui sont censées protéger l’individu et son intégrité. C'est le cas des capteurs qui vont se répandre dans notre corps.

Comment se sortir du bourbier Cobol
Cela fait 30 ans que l'on supporte le poids des applications Cobol, écrites entre les années 70 et 2000. Il est temps de les transposer, ne serait-ce que parce qu'elles ne sont plus conformes à la règlementation.

Travail à distance, allons-nous tous devenir fous
Le covid a au moins montré une chose, que les êtres humains, si on leur en donne les moyens, sont parfaitement capables de travailler à distance. Ce qui n'est cependant pas sans risque. L'expérience l'a montré.

Méthodes agiles, pourquoi tant de haine
On ne sait pas pourquoi, mais les informaticiens ont le génie pour trouver des sujets de polémiques là où il n'y en a pas. C’est le cas de l'agilité qui suscite des torrents de haine et d’incompréhension.

Le bilan d'une année riche en émotions
Avant de clore 2021 qui ne nous aura pas laissé que des bons souvenirs, dressons l'inventaire des faits marquants qui se sont produits tout au long de l'année, en espérant que les innovations de 2022 ne soient pas liées aux nouveaux variants du covid.

Le poste de travail Linux, une réalité incontournable
Le rôle d'un système d'exploitation n'est plus le même aujourd'hui par rapport à ce qu'il était au siècle dernier. Il n'est plus qu'un banal fournisseur de services, l'essentiel se situant ailleurs, dans le navigateur Internet.

Les incroyables progrès des neurosciences
Ne touchez pas à mon cerveau : je ne sais même pas comment il fonctionne !!! Dans le sillage des compagnies GAFAM spécialisées dans les communications avec le cerveau, il faut s'attendre à des bouleversements extraordinaires.

Starlink d'Elon Musk, une révolution encore incomprise
On peut penser qu'Elon Musk est un illuminé, pour le moins qu'il véhicule des idées folles. On peut aussi penser que la terre est plate. Car Elon Musk, que cela plaise ou non, est en train de révolutionner le monde dans lequel nous vivons. Ses initiatives sont marquantes, à commencer par Starlink.

Les métiers nouveaux de demain
C'est bien connu, l'Intelligence Artificielle va supprimer des millions d'emplois et une réplique de la crise de 29 est aux portes de nos entreprises. C'est faux et si l'IA va effectivement supprimer certains emplois, elle va en créer de nombreux autres.
Pour nos abonnés
- Suivez LeMarson en direct
- Accédez à des centaines de dossiers et d'articles
- Visionnez des dizaines d'heures de formations vidéos
- Téléchargez le Livre des tendances de l'année