
Tout savoir sur le « machine learning » (II), training-set, sous-apprentissage et sur-apprentissage
Un processus de « machine learning » a pour finalité d’apprendre à un algorithme à faire des prévisions sur un sujet donné, en s’appuyant sur un modèle. L’un des modes utilisés, le plus courant en 2018, est dit supervisé, en ce sens qu’il est fondé sur des jeux de données (datasets), caractéristiques du sujet traité, fournis éventuellement par des prestataires externes, qui permettent à l’algorithme de se « familiariser » avec l’objectif.
Il s’agira par exemple d’une bibliothèque d’images, d’un ensemble de comportements, d’alertes significatives pour comprendre une fraude, de symptômes pour la détection de maladies, etc.
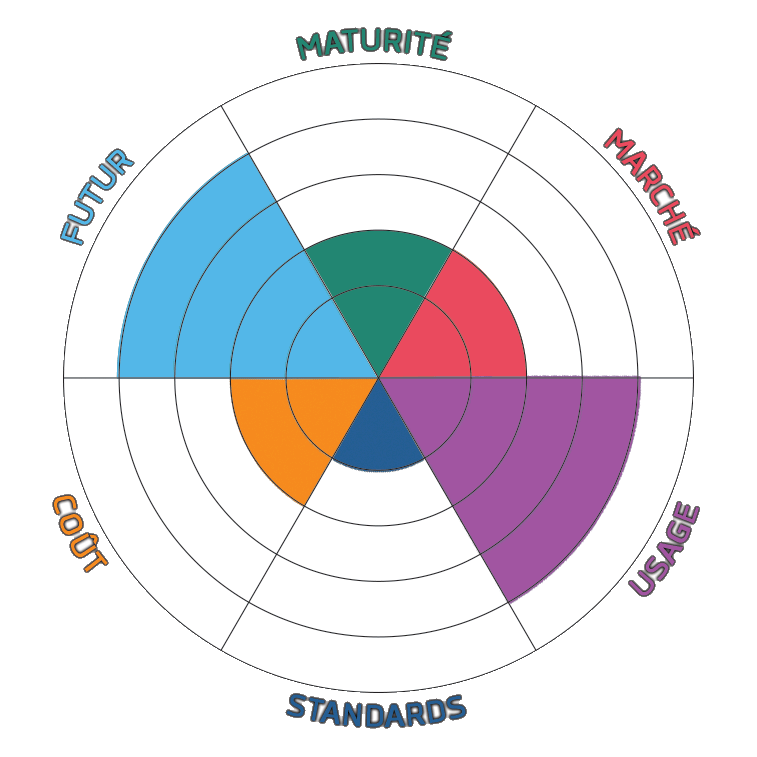
Les critères sont évalués de 1 à 5
- Marché
- Présence réelle sur le marché.
- Usage
- Intérêt potentiel, hors considérations commerciales
- Standards
- Niveau de standardisation du sujet
- Coût
- Intérêt potentiel, hors considérations commerciales
- Futur
- Niveau de crédibilité prévisible
- Maturité
- Niveau de maturité atteint actuellement
Comprendre le modèle en couches des "generative AI "
Les données personnelles : une bataille perdue d'avance
Intelligence Artificielle : l'énigme de la conscience
DAS cellulaire : les architectures distribuées d'antennes
Module ARCHITECTURES du système d’information et technologies du datacenter